SDK NPU工具链
致力于简化模型从量化到部署的流程。
1. 概述
TACO SDK 提供的 NPU 神经网络工具链是一套强大而全面的开发工具集,旨在赋能开发者将主流 AI 框架下训练完成的神经网络模型,高效、无缝地迁移并部署到特普斯微(TOPSFuture)的 AI SoC 芯片上。本工具链致力于简化模型从训练到端侧部署的复杂流程,充分释放 NPU 的硬件加速潜能。
NPU工具链主要特点:
-
广泛的框架兼容性: 无缝对接主流 AI 训练框架,包括 TensorFlow, PyTorch, ONNX, Caffe, Keras, TFLite 及 Darknet 等,轻松导入您现有的模型资产。
-
自动化模型转换: 提供将不同框架模型自动转换为优化后、适配 NPU 硬件执行的统一内部表示能力。
-
深度优化与量化: 集成了先进的模型优化技术,包括多种策略的模型量化(如 FP16/INT8 等),显著降低模型计算量和内存占用,提升推理速度,同时尽可能保持模型精度。支持模型剪枝等其他优化手段。
-
特别支持 FP16 (半精度浮点) 量化: FP16 量化能够在提供接近原始 FP32 模型精度的同时,显著减少模型部署后的精度调优工作量。对于追求高精度且希望缩短开发周期的应用,FP16 是一个理想的选择,能够帮助您更快地将高质量 AI 功能推向市场。
-
完善的仿真验证: 允许开发者在部署到实际硬件前,在开发环境中进行模型推理仿真与精度验证,便于调试、性能调优和算法迭代。
-
一键式部署生成: 能够将优化后的模型导出为目标平台所需的运行时库和应用程序代码框架,简化最终在 NPU 上的集成与部署工作。
2. 核心使用流程
NPU工具链的核心工作流程如下图所示,主要包含模型在 PC 端的离线编译过程和在设备端的在线推理过程:
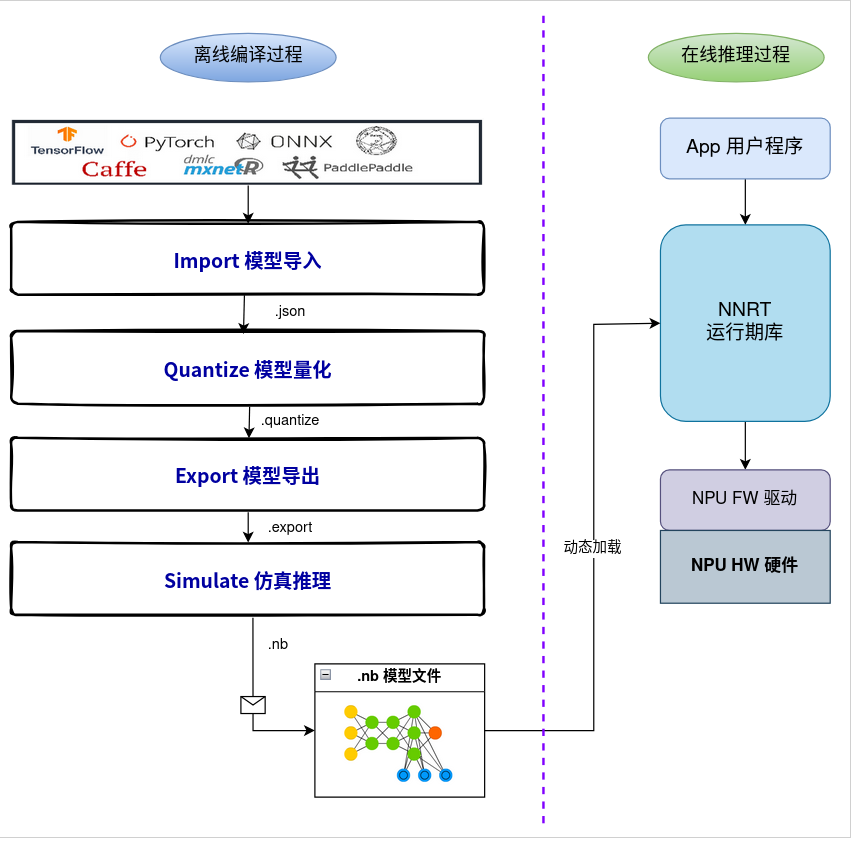
3.离线编译阶段(PC端)
-
模型导入 (Import): 支持导入来自 TensorFlow, PyTorch, ONNX, Caffe, TFLite, Keras, Darknet 等多种主流框架的预训练模型。
-
模型量化 (Quantize): 提供灵活的量化选项,支持 INT8, UINT8, INT16 等多种数据类型,以及 Normal, KL散度 , Moving Average 等量化算法。特别地,工具链支持 FP16 (半精度浮点) 量化,能在保证较高精度的同时显著减少精度调优工作,加速产品化进程。
-
模型导出 (Export): 将优化和量化后的模型导出为 NPU 可执行的格式,如 .nb (Network Binary Graph) 文件,用于设备端部署。
-
仿真推理 (Simulate): 在 PC 端模拟 NPU 推理过程,方便进行精度验证和调试。
4.在线推理阶段(设备端)
-
用户应用程序 (App) 调用 runtime库 (神经网络运行时库)。
-
Runtime动态加载离线编译生成的 .nb 模型文件。
-
Runtime通过 NPU 固件驱动 (NPU FW Driver) 调用 NPU 硬件 (NPU HW),高效执行模型推理。
更详细的NPU工具链以及相关文档,请联系销售获取。